On occasion of SIGMOD 2012, I thought I'd write up a short post about a new project, Skimmer.
 When considering challenges of ad-hoc, end-user interaction with databases, user actions can be broadly categorized into three groups: (1) explicit, articulate querying of the database, (2) searching through the database, and (3) browsing through the database. Prior work in the area of database usability has recognized (2: Searching) and (3: Browsing) as being significant challenges. My dissertation work attempted to solve (2: Searching) using a combination of autocompletion and qunits. The Skimmer project looks at (3: Browsing). In our SIGMOD 2012 paper, we introduce a method that makes it easier for users to browse large datasets. Here's the abstract and the intuition behind it, followed by a cool demo video of a new implementation of Skimmer:
When considering challenges of ad-hoc, end-user interaction with databases, user actions can be broadly categorized into three groups: (1) explicit, articulate querying of the database, (2) searching through the database, and (3) browsing through the database. Prior work in the area of database usability has recognized (2: Searching) and (3: Browsing) as being significant challenges. My dissertation work attempted to solve (2: Searching) using a combination of autocompletion and qunits. The Skimmer project looks at (3: Browsing). In our SIGMOD 2012 paper, we introduce a method that makes it easier for users to browse large datasets. Here's the abstract and the intuition behind it, followed by a cool demo video of a new implementation of Skimmer:
A relational database often yields a large set of tuples as the result of a query. Users browse this result set to find the information they require. If the result set is large, there may be many pages of data to browse. Since results comprise tuples of alphanumeric values that have few visual markers, it is hard to browse the data quickly, even if it is sorted.
In this paper, we describe the design of a system for browsing relational data by scrolling through it at a high speed. Rather than showing the user a fast-changing blur, the system presents the user with a small number of representative tuples. Representative tuples are selected to provide a “good impression” of the query result. We show that the information loss to the user is limited, even at high scrolling speeds, and that our algorithms can pick good representatives fast enough to provide for real-time, high-speed scrolling over large datasets.
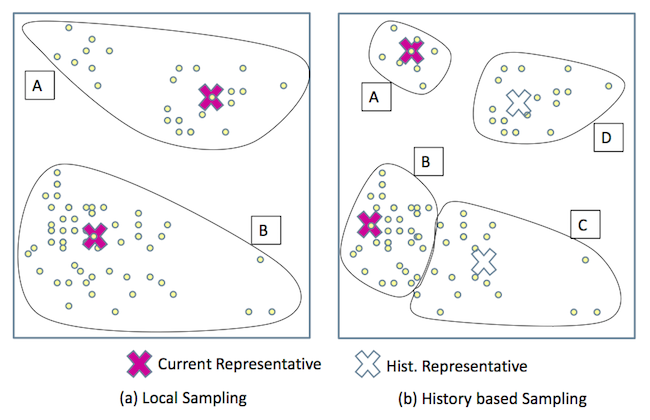
The intuition behind picking representative tuples is simple: Since pages will be consumed in succession, we represent a sampled overview of the current page, but it is a good idea to bias the samples such that we avoid (re)showing information provided in the prior pages. Thus, we promote tuples that increase the information provided to the user compared to the prior pages: i.e. minimize the information loss. The paper evaluates this idea against varying scrolling speed, page size, number of attributes and information quality.
The video above demonstrates the new version of Skimmer we've been working on at Ohio State. Similar to the original Skimmer system, it initially only shows you representative tuples from a page, loading and rendering in the rest of the data in a lazy fashion. Non-rendered tuples are shown as grey bands, for clarity.
This project falls under the "Surfacing of Insights" section of the roadmap laid out in the Guided Interaction VLDB 2011 vision paper, and is only the first step in what I hope is an engaging conversation in the area of large-scale data browsing.
And of course, if you are a current student at Ohio State looking to work on cool projects such as this one, I am looking for students to join my research group. Drop me a line!