In my line of work I often encounter the need to sort multi-gigabyte files that contain some form of tabulated text data. Usually, one would do this using a single unix sort command, like this:
sort data.tsv -o data.tsv.sorted
Even with an adequate machine, this takes 21 minutes for a 7.4GB file with 115M objects. But like most moderate-sized work machines these days, we have multiple cores(2xQuad Intel Xeon), abundant memory(24G) and a fast disk(15K RPM), so running a single sort command on a file is serious underutilization of resources!
Now there’s all sorts of fancy commercial / non-commercial tools that can optimize this, but I just wanted something quick and dirty. Here’s a quick few lines that I end up using often that I thought would be useful to share:
split -l5000000 data.tsv '_tmp';
ls -1 _tmp* | while read FILE; do sort $FILE -o $FILE & done;
Followed by:
sort -m _tmp* -o data.tsv.sorted
This takes less than 5 minutes!
How this works: The process is straightforward; you’re essentially:
1. splitting the file into pieces
2. sorting all the split pieces in parallel to take advantage of multiple cores (note the “&”, enabling background processes)
3. then merging the sorted files back
Since the speedup from the number of cores outweighs the cost of increased disk I/O from splitting / merging, you have a much faster sort. Note the use of while read; this ensures that just-created files don’t get considered, avoiding infinite loops.
For fun, here’s a screen cap of what I’d like to call the “Muhahahahaha moment” — when the CPU gets bombarded with sort processes, saturating all cores:
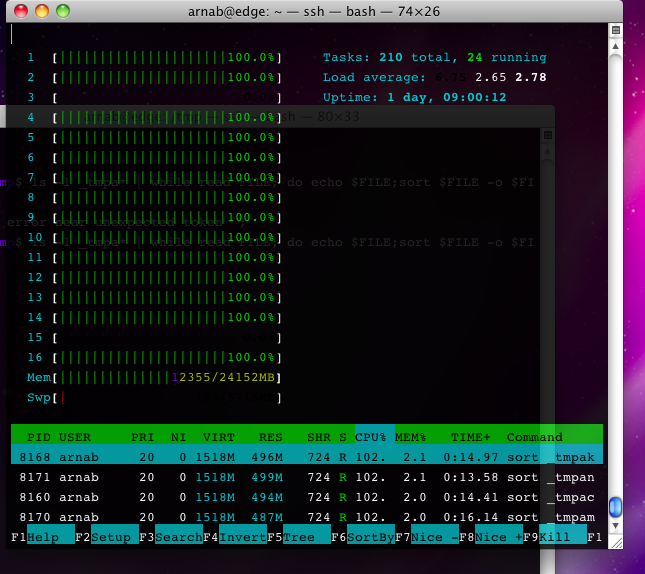
(see video version of this , you’ll need to skip to 00:36s mark)
What other people have to say:
what command do you use to show the last screen? is it some special option for top?
It’s an alternative process viewer called htop — I highly recommend it!
Man page said “sort -m” does not do sort; if so, the merged results are not sorted.
If you fire off more processes than cores, don’t you get a lot of swapping (certainly each time sort does i/o)?
I just used your trick (which was neat!), but split my files into 4 pieces because I have 4 cores and didn’t want to swap; still get 100% across the board, of course!
@anon 1: Indeed, “sort -m” does not sort, it merges already sorted results. Since we start off with sorted results (from the previous sort), the merged results are thus also sorted. You can verify this by running a “sort -c”.
@anon 2: Yes, you don’t want too many processes. The ideal number of processes vs number of cores relationship isn’t always 1:1, so the best bet is to try it a few times and pick the fastest config.